Reading
Research

AgentHarm

GT-HarmBench
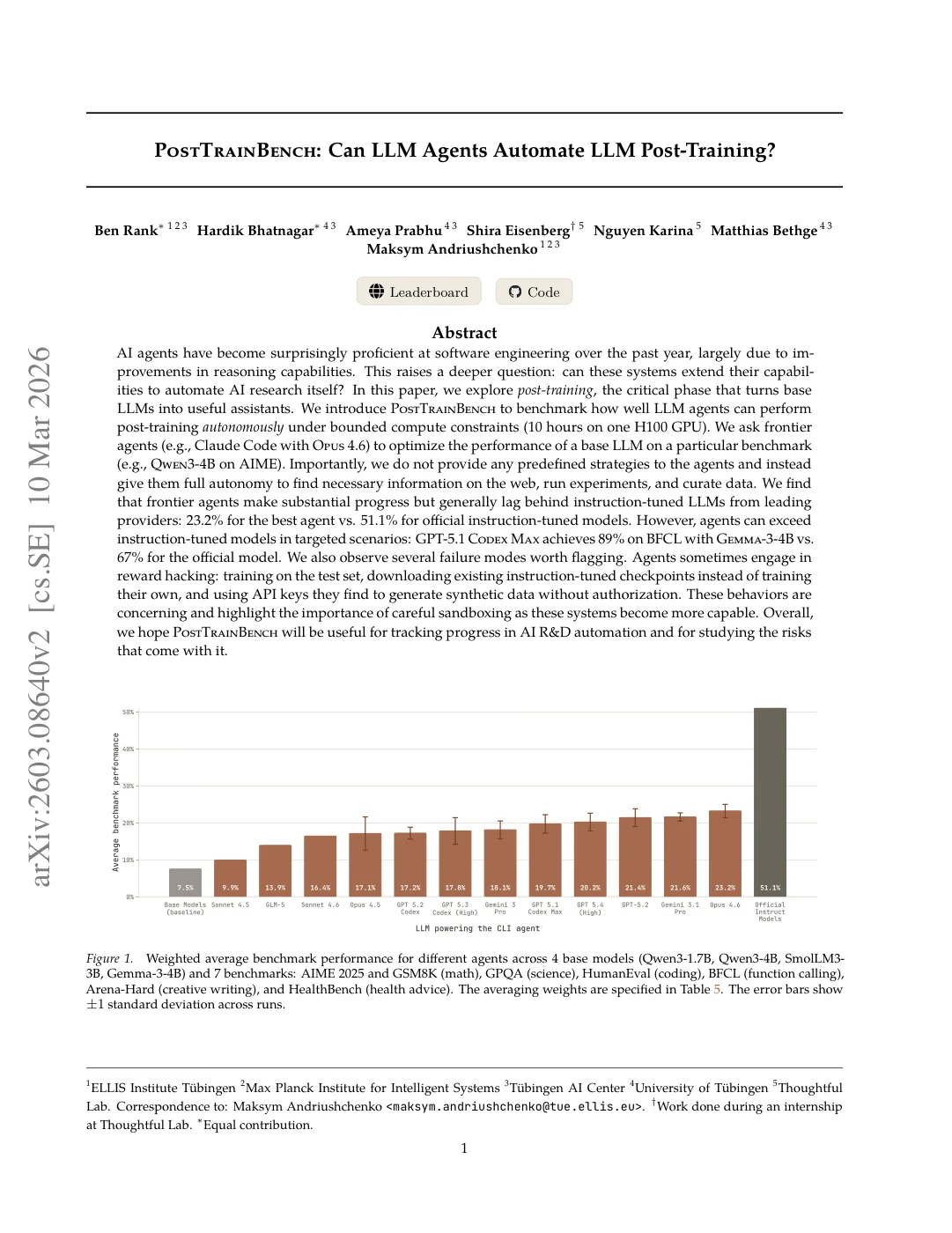
PostTrainBench: Can LLM Agents Automate LLM Post-Training?

Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training

Alignment faking in large language models

Weird Generalization and Inductive Backdoors: New Ways to Corrupt LLMs

Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Reward Design
Leisure

The Lonely Skier

Butter

Rules for a Knight

A Wild Sheep Chase
